一、基础概念
二、Flink 流处理 API
2.1 Environment
获取执行环境:本地?集群?
2.2 Source
从不同的数据源获取数据
2.3.1 基本转换算子
2.3.2 聚合算子
DataStream 需要现分组才能做聚合操作
先 keyBy 得到 KeyedStream,再调用 reduce、sum 方法
- keyBy
- Rolling Aggregation
- sum()、min()、max()、minBy()、maxBy()
- 滚动聚合,来一个数据更新一次结果
- reduce
2.3.3 多流转换算子
Split 和 Select(已废弃)
- split 将 DataStream 中的数据拆到一个 SplitStream 中的两部分
- Select 将 SplitStream 中的数据,提取成多个 DataStream
Connect 和 CoMap
- 与 Split、Select 相对,将两条Stream合并为一个Stream
- connect 将两个 stream 合并成 ConnectedStreams 中的两部分
- CoMap 将ConnectedStreams 中的两部分,合并为一个 DataSteam
Union
- 对两个或者两个以上的DataStream进行Union操作
- 与 Connect 区别
- Connect 的数据类型可以不同,Connect 只能合并两个流
- Union可以合并多条流,Union的数据结构必须是一样的
2.3.4 算子转换关系

2.4 支持的数据类型
2.5 实现 UDF 函数
2.6 数据重分区
2.7 Sink
2.7.1 Kafka Sink
- pom 依赖
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| <?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.shuofxz</groupId>
<artifactId>FlinkTutorial</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.12</artifactId>
<version>1.10.1</version>
</dependency>
</dependencies>
</project>
|
- Java 代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| package com.shuofxz.sink;
import com.shuofxz.beans.SensorReading;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer011;
import java.util.Properties;
public class kafkaSink {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "hadoop102:9092");
properties.setProperty("group.id", "consumer-group");
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("auto.offset.reset", "latest");
DataStream<String> inputStream = env.addSource( new FlinkKafkaConsumer011<String>("sensor", new SimpleStringSchema(), properties));
DataStream<String> dataStream = inputStream.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2])).toString();
});
dataStream.addSink( new FlinkKafkaProducer011<String>("hadoop102:9092", "sinktest", new SimpleStringSchema()));
env.execute();
}
}
|
- 启动 zookeeper、kafka 服务
- 启动 kafka 生产者 & 消费者
新建kafka生产者console
1
| $ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic sensor
|
新建kafka消费者console
1
| $ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic sinktest
|
- 运行Flink程序,在kafka生产者console输入数据,查看kafka消费者console的输出结果
输入(kafka生产者console)
1
2
| >sensor_1,1547718199,35.8
>sensor_6,1547718201,15.4
|
输出(kafka消费者console)
1
2
| SensorReading{id='sensor_1', timestamp=1547718199, temperature=35.8}
SensorReading{id='sensor_6', timestamp=1547718201, temperature=15.4}
|
这里Flink的作用相当于pipeline了。
2.7.2 Redis Sink
2.7.3 ES Sink
2.7.4 JDBC Sink
三、Flink Window
3.1 Window 概述
将无限数据流切割为有限数据块的操作。Window将一个无限的stream拆分成有限大小的”buckets”桶,我们可以在这些桶上做计算操作。
3.1.1 类型
- 时间窗口(Time Window)
- 计数窗口(Count Window)
TimeWindow:按照时间生成Window
CountWindow:按照指定的数据条数生成一个Window,与时间无关
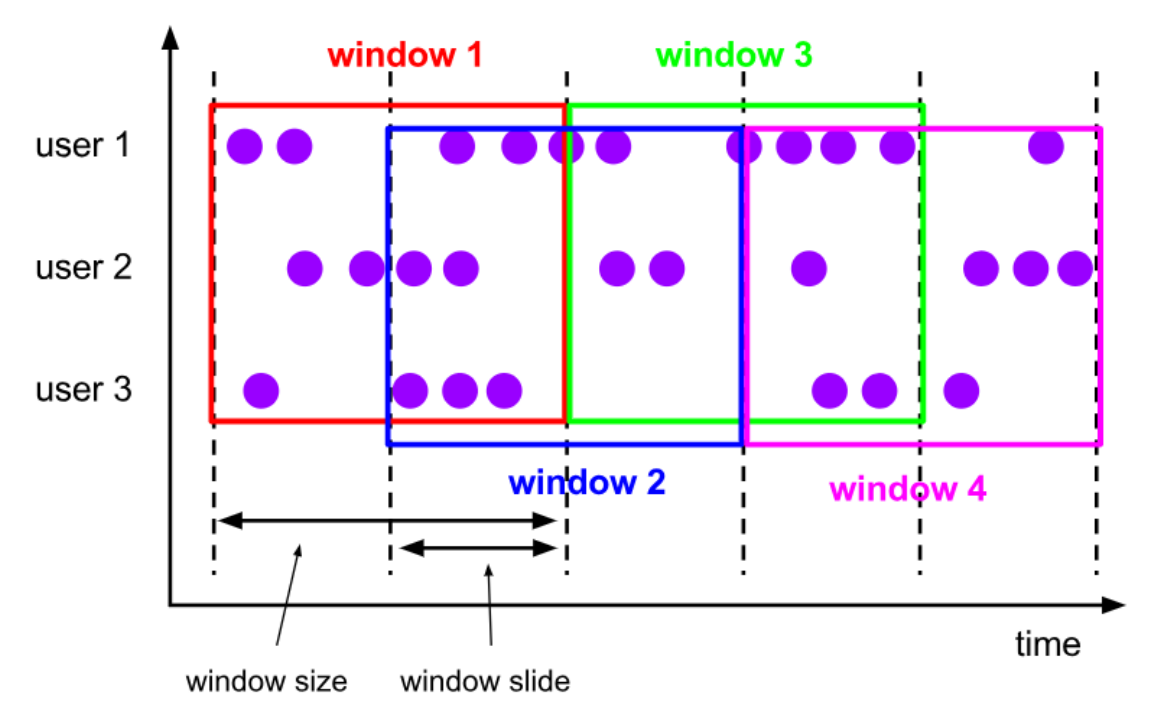
滚动窗口(Tumbling Windows)
- 依据固定的窗口长度对数据进行切分
- 时间对齐,窗口长度固定,没有重叠
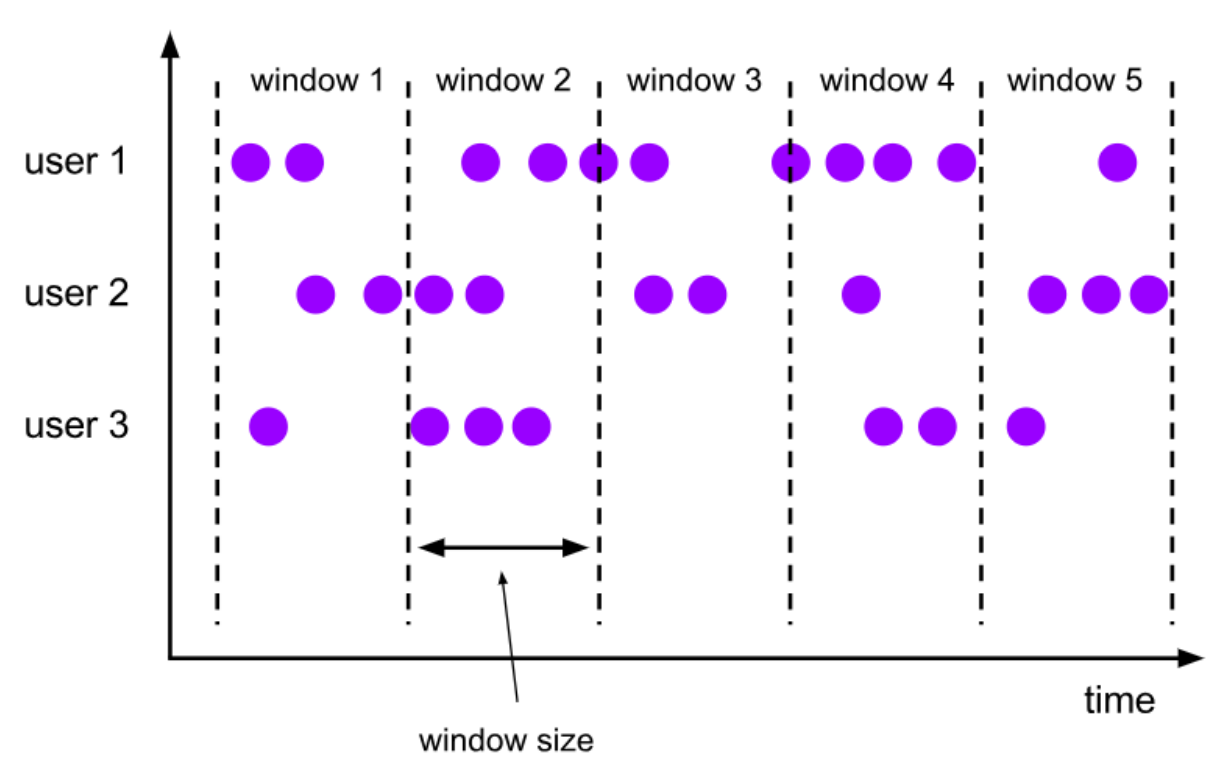
滑动窗口(Sliding Windows)
- 可以按照固定的长度向后滑动固定的距离
- 滑动窗口由固定的窗口长度和滑动间隔组成
- 可以有重叠(是否重叠和滑动距离有关系)
- 滑动窗口是固定窗口的更广义的一种形式,滚动窗口可以看做是滑动窗口的一种特殊情况(即窗口大小和滑动间隔相等)
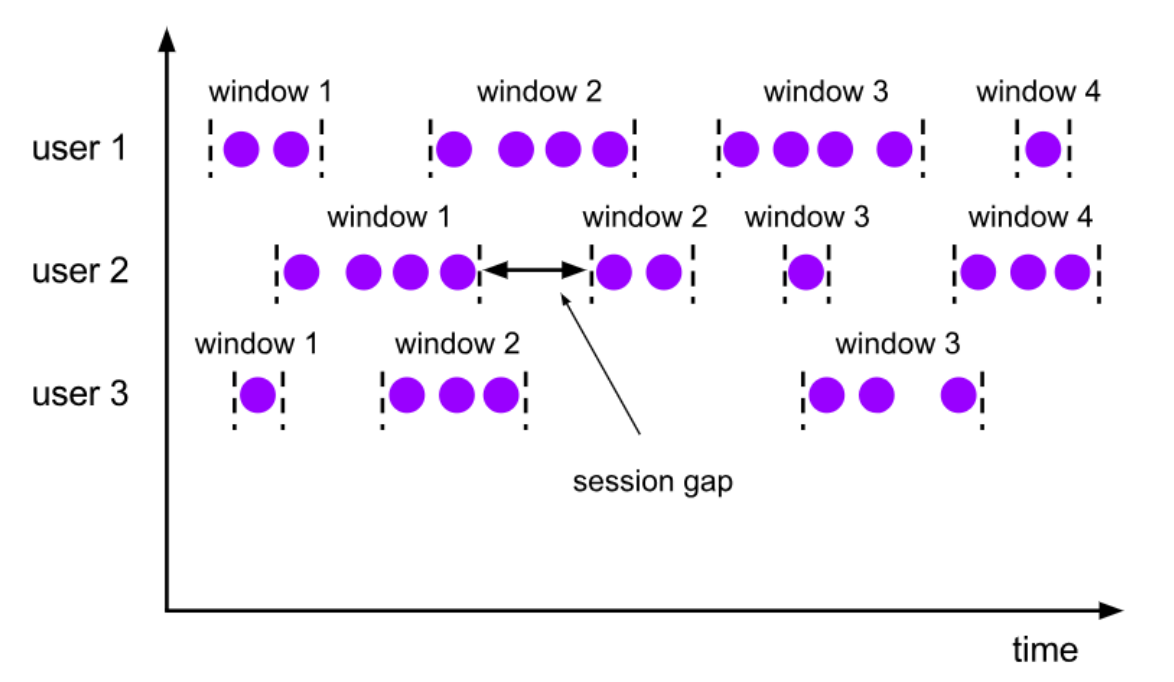
会话窗口(Session Windows)
- 由一系列事件组合一个指定时间长度的timeout间隙组成,也就是一段时间没有接收到新数据就会生成新的窗口
- 特点:时间无对齐
3.2 Window API
四、时间语义 & Watermark
4.1 Flink中的时间语义
- Event Time:事件创建时间
- Ingestion Time:数据进入Flink的时间
- Processing Time:执行操作算子的本地系统时间,与机器相关
Event Time是事件创建的时间。它通常由事件中的时间戳描述,例如采集的日志数据中,每一条日志都会记录自己的生成时间,Flink通过时间戳分配器访问事件时间戳。
4.2 Watermark
4.2.1 概念及作用
出现原因:用于处理网络延迟、分布式延迟等造成的数据乱序问题
工作方式:
- 伪装成一个普通数据插入到数据流中,基本只包含时间信息
- Flink 读到 watermark 证明该 watermark 中时间点前的数据已全部到达,可以关闭对应的 bucket 进行处理
- 为了能够尽量包容延迟数据,会将 watermark 的时间比实际收到的数据时间慢一些(如2-3s),这样就可以把几秒内的延迟数据包容进来了
- 猜测:如果延迟时间过长,超过了 watermark 设置的时间,就会被丢弃
Flink流计算编程–watermark(水位线)简介
五、Flink 状态管理
状态:相当于是之前task留下来的数据,用于和新的数据流数据进行计算用的?